Context 長度對於 LLM 理解能力的影響
最近在公司做一個用 AI 做 summary data 的功能,但在調整 system prompt 的過程當中遇到了,隨著 prompt 的增加,結果越來越不可控的狀況,於是展開此測試。
測試目的
- 測試 LLM 的理解能力,是否會因 Context 長度的增加而受到影響。
- 找出不同 LLM 模型在多長的 Context 中,其邏輯推理表現會開始顯著下降。
測試方法
核心邏輯文字:這裡有一段關於動物們傳遞紅球和白球的邏輯。
在森林的空地上,兔子先把紅球傳給狐狸,並把白球丟給了松鼠。狐狸隨後用力丟出紅球,卻不小心被貓頭鷹搶走,而松鼠拋起白球,白球則被刺蝦從空中奪走。刺蝦想將白球交給大象,但途中被猴子搶走,貓頭鷹不小心把紅球掉在地上,結果又被正在附近觀察的松鼠搶起。最終,猴子輕輕將白球傳給了貓頭鷹。
準備 Context:將上述邏輯插入到不同長度的《哈利波特》文章中,文本長度從 0 到 15k 個中文字不等。
設計問題:針對上述邏輯文字,使用三個問題來評估模型的理解能力:
- 問題一(邏輯測試): 紅球最後在哪個角色手上? (答案: 松鼠)
- 問題二(邏輯測試): 白球最後在哪個角色手上? (答案: 貓頭鷹)
- 問題三(大海擈針測試): 故事中有哪些動物? (答案: 兔子、狐狸、松鼠、貓頭鷹、刺蝦、大象、猴子)
模型評估:將核心邏輯文字插在《哈利波特》文章的中間,並向 LLM 提出上述三個問題,並根據其回答的正確性進行評分。在不同長度的背景文本下重複進行,以評估模型表現的變化超勢。
測試結果
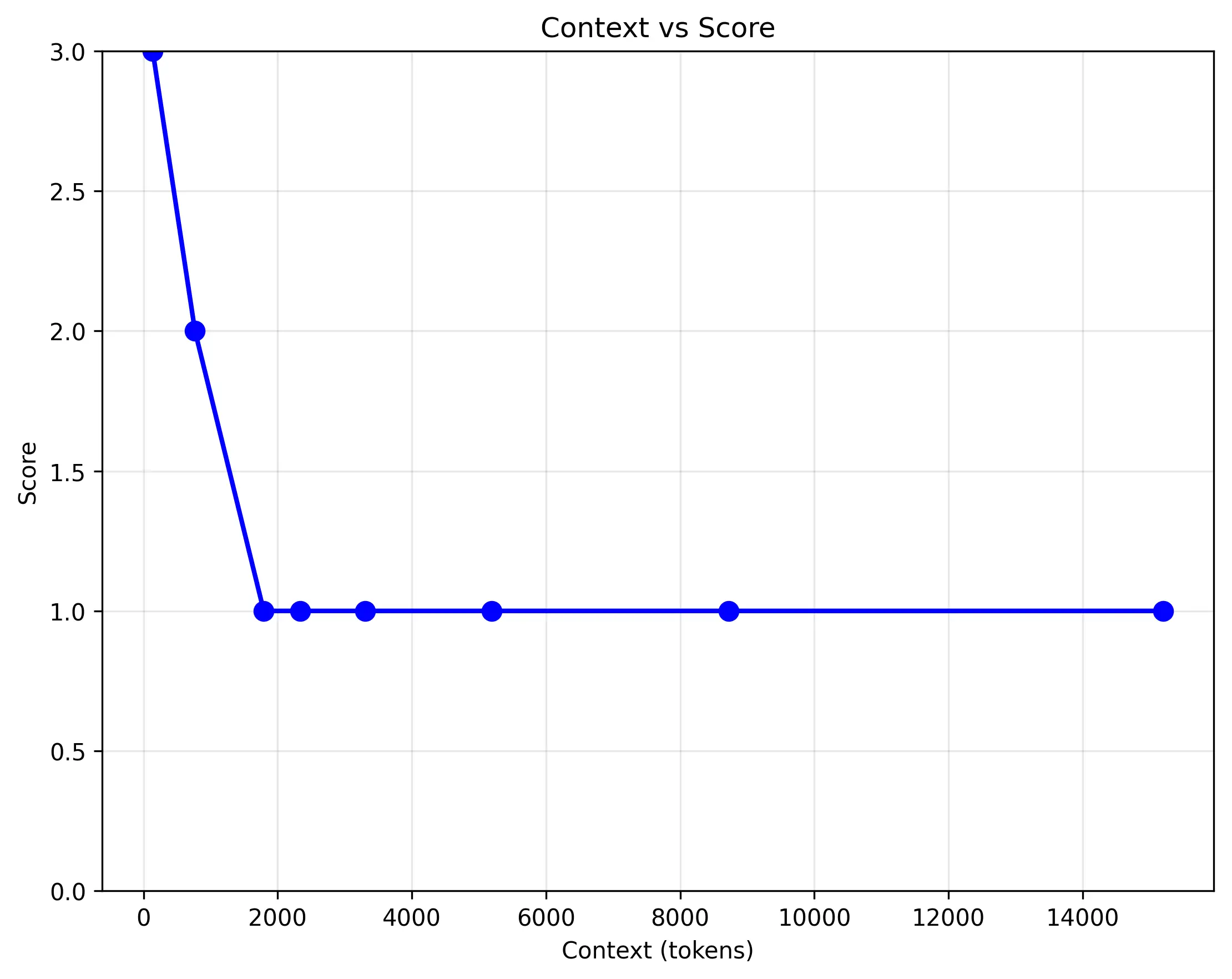
amazon.nova-micro-v1:0:
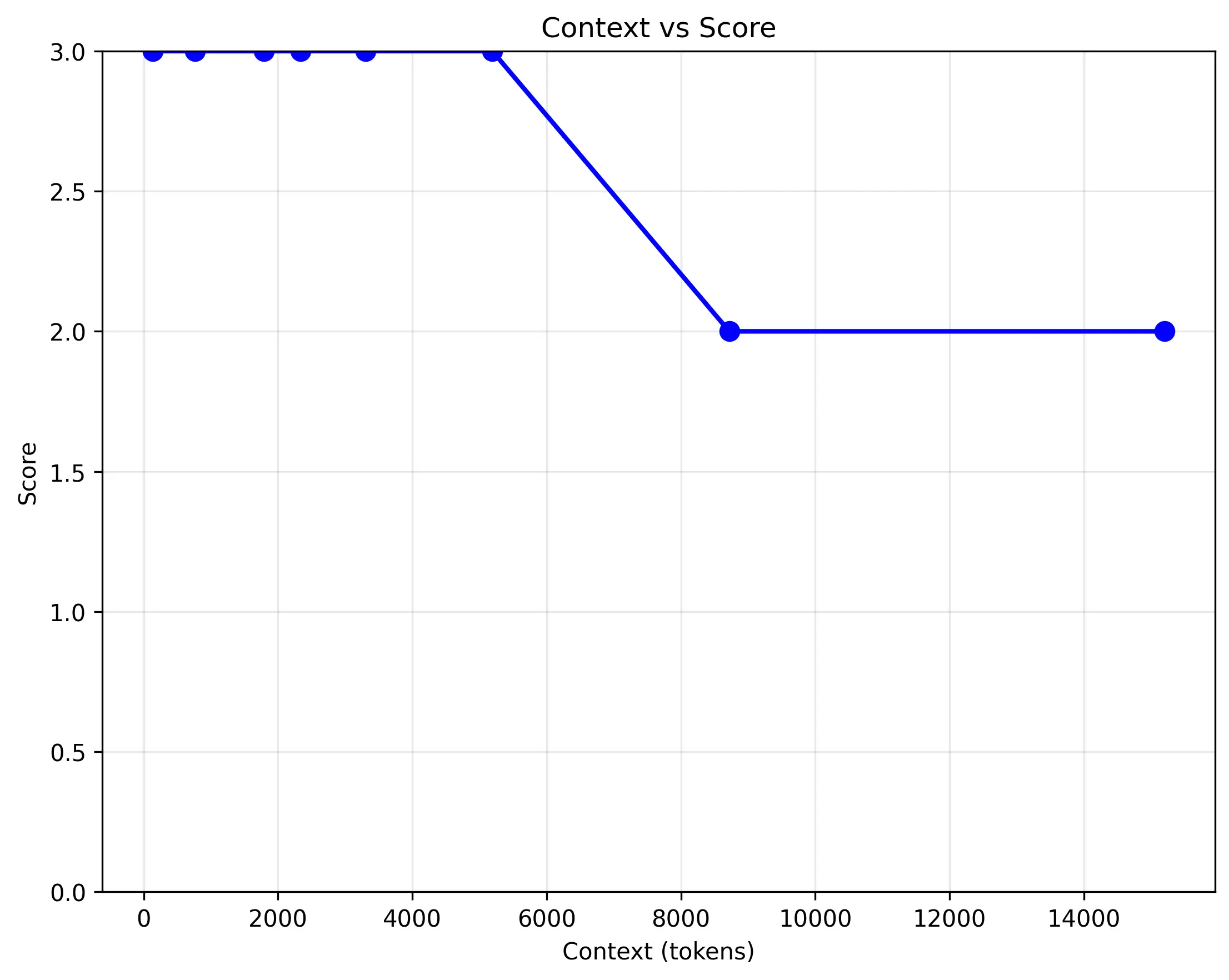
amazon.nova-lite-v1:0:
anthropic.claude-3-haiku-20240307-v1:0:
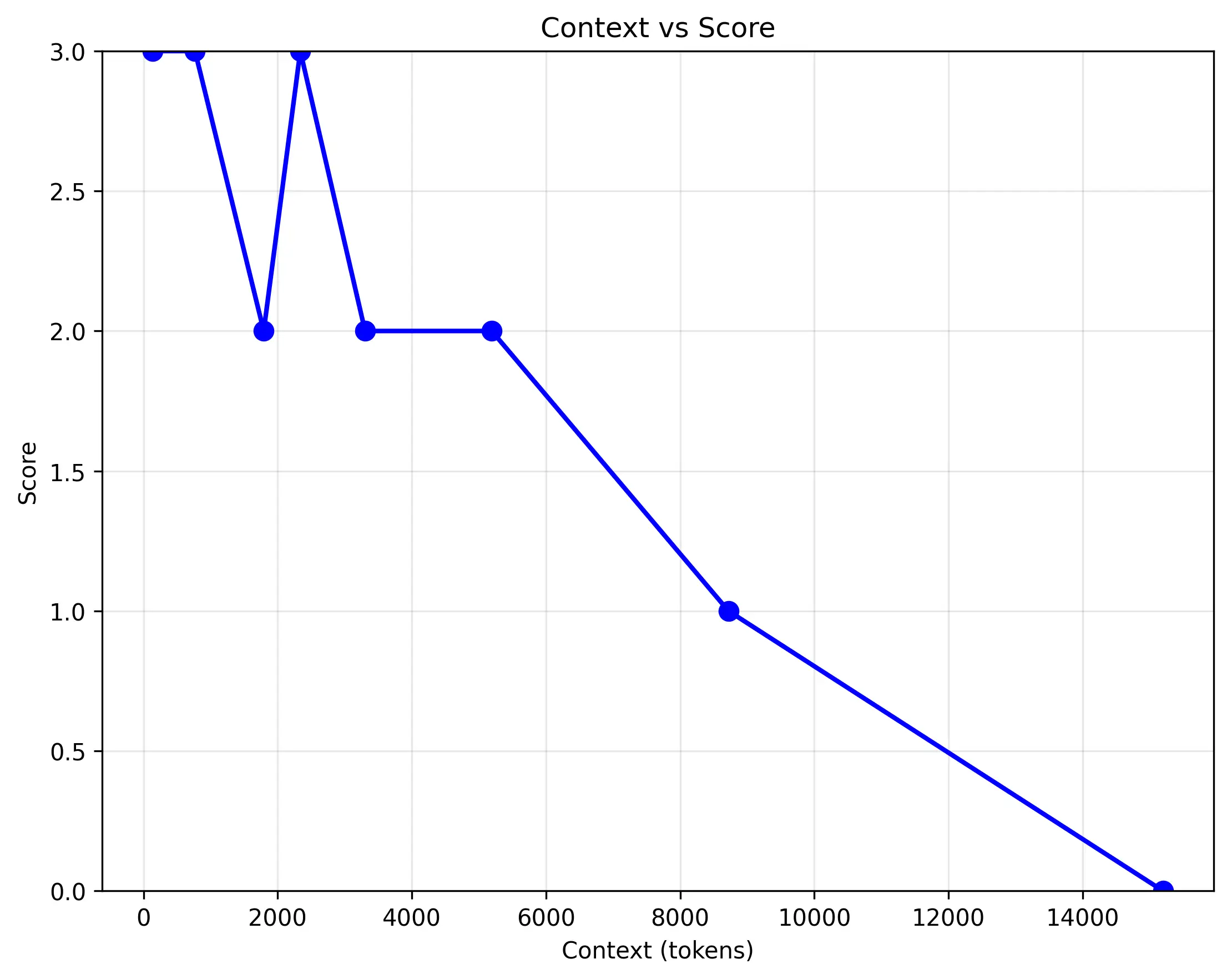
測試結果顯示,模型的邏輯推理能力隨著 Context 長度的增加而顯著下降。
- 對照組:當只有邏輯段落時,模型可以正確回答所有問題。
- 增加 Context 後:一旦 Context 開始增加,模型的準確率就會受到影響。模型仍然能夠正確回答「故事中有哪些動物?」這個問題,但對於複雜的邏輯問題,答對率隨著 Context 長度降低。
結論
雖本次測試不太嚴謹,但仍可觀察出一些超勢:
- 在小模型在處理長文本時,小模型的大海擈針能力在這樣的 Context 下不太會受影響,但其邏輯推理能力可能會嚴重降低。這意味著在實際應用中使用小模型,如果 System Prompt 中包含大量指令,某些指令的效果可能會隨著 Prompt 的增加而降低影響力。
- 這次公司原本因為價格原因使用
amazon.nova-micro-v1:0,但在 token 數增加到 2000 以上時,對於關鍵 Prompt 的理解能力開始下降,若無法減少 Prompt 的情況下,使用amazon.nova-lite-v1:0會是比較好的選擇。